Skip to main content
A major international transportation company was processing vast volumes of heterogeneous real-time data across multiple fragmented systems. Their heavy reliance on Oracle infrastructure created crippling licensing costs that limited scalability. Business teams needed real-time actionable insights, but legacy architecture bottlenecks meant data was always arriving too late to drive decisions.
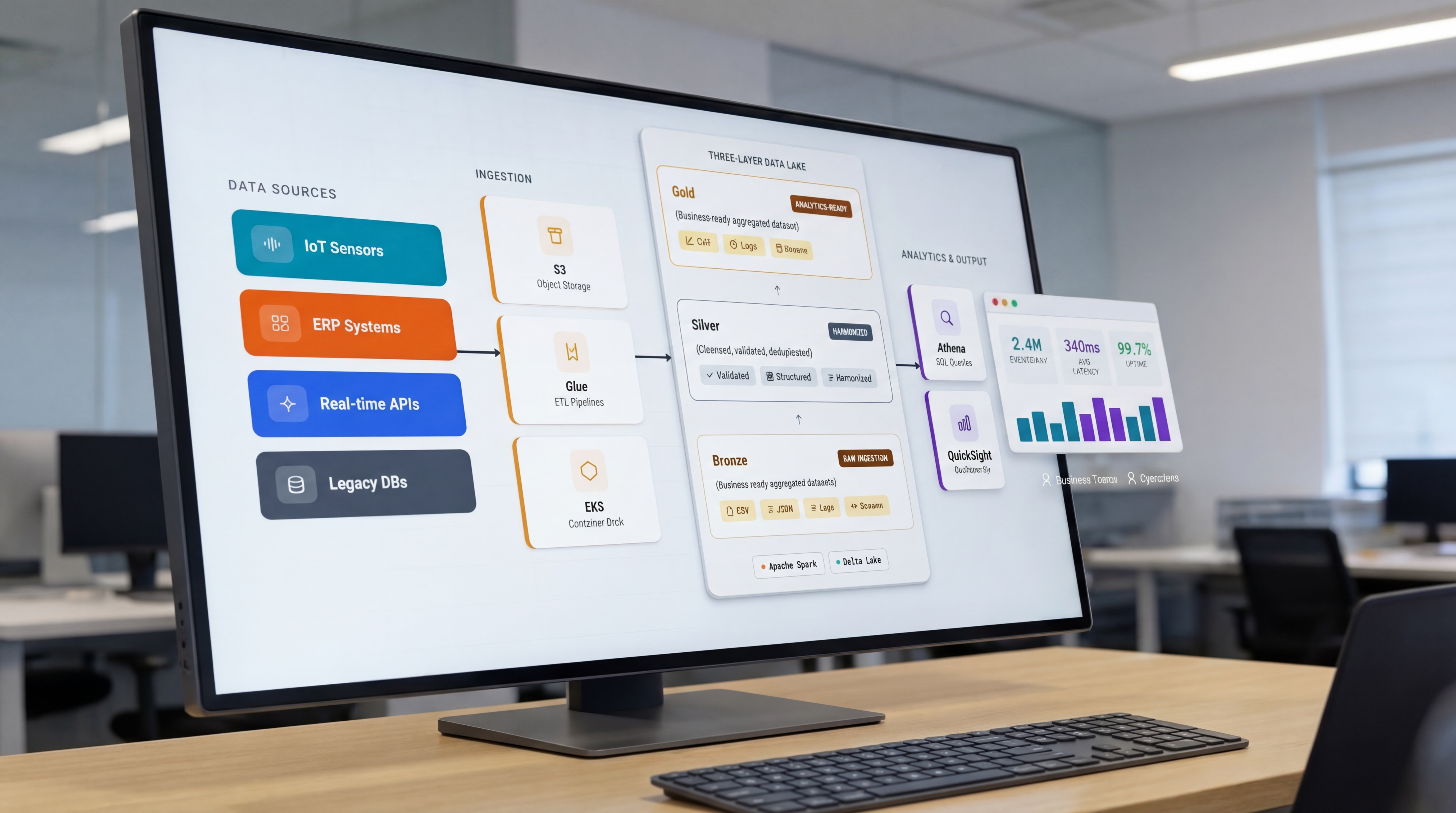
We designed and deployed a cloud-native data lake on AWS with a structured three-layer architecture — Bronze for raw data ingestion, Silver for cleansed and harmonized data, and Gold for business-ready analytical datasets. Automated ETL pipelines replaced manual processes, and the entire Oracle-dependent infrastructure was migrated to a modern, flexible data stack.
The platform leverages Apache Spark for distributed processing, Delta Lake for reliable data storage, and AWS services including EKS, EMR, S3, Glue, Athena, and QuickSight for end-to-end data operations — from ingestion to visualization.
The migration delivered massive cost savings through Oracle license elimination while providing clean, harmonized data with business-ready insights. The architecture is now scalable and future-proof, capable of growing with business demands. Time-to-insight was dramatically accelerated, enabling the operations team to make data-driven decisions in near real-time instead of waiting days for reports.